


The Unexpected
How long can your business survive without an online presence? How much money is lost every minute your site(s) are down? These are questions every business should be asking. If you don’t think the unexpected could happen, just look what COVID19 did. While that didn’t negatively impact the Cloud, its the most recent example of how easy our lives can be turned upside down. Between natural disasters, man-made ones, major internet failures, and many other reasons why your site(s) might catastrophically fail, it’s really only a matter of time before your number is up.
The Plan
At Hostek, our Cloud engineers have come up with a fully automated, fully managed, fully redundant, and fully secure DR plan for all of your critical applications. With Geo-Failover, an entire region could go offline, but your Windows or Linux applications will remain online, by quickly shifting to another one of our Cloud locations, with virtually no downtime whatsoever. As you continue reading about the details of our DR solution, don’t let the technical complexities intimidate you. We will completely setup, maintain, and monitor the entire solution.
Global Presence
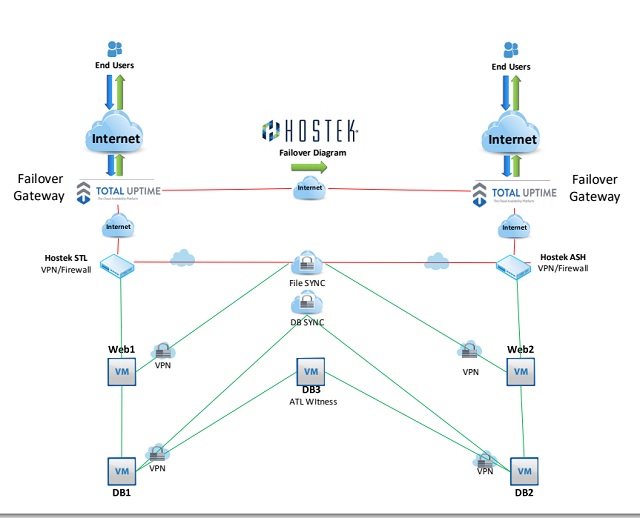
The DR solution begins with the most important part, the Geo-Failover router. It’s important because it handles a lot of the failover automation we need, while not being a single point of failure itself. There would be no point in having a failover solution where the first node wasn’t even failover capable. In this case, the Failover router isn’t actually just one router, nor does it need to failover. It’s several routers, strategically placed all over the world, but still able to share one IP address. If a router were to fail in one area, you would just connect to the same router in another area. This networking feature is called Anycast, and it is primarily used by large CDN providers and global anti-DDOS networks. Total Uptime saw the potential and provides the perfect solution for our failover needs.
Three of a kind
The next requirement to this solution is having 3 Datacenters in separate regions. One to be primary, one to be secondary, and the third to act as a witness. These locations should not be close enough to be affected by the same outage, but not far enough away that latency will cause slowness. Currently, these 3 locations will be in our STL, ASH, and ATL Datacenters. To connect these Datacenters together, and to make sure your data isn’t exposed to the public, we create dedicated virtual private networks between all locations. The primary Datacenter location will hold your primay Web and DB server, but you are not limited to that. We would then clone your primary servers to the secondary location and assign new IP addresses. The third location just needs one starter level VM, the purpose I will discuss later. Once we make sure that all VM’s can communicate securely over the private network, we move on to synchronizing the data and services.
Twins
Now that we have the framework and a secure way to transmit data between Datacenters, we need to keep the web servers synchronized. If a failover were to occur, you wouldn’t want any data to be missing. To avoid that, we use special software that can synchronize data in near real-time. That way, any changes you make to your sites are fully replicated without delay. We also have the ability to sync IIS, ColdFusion, Apache, and any other directory. If necessary, we can exclude directories, file names, and file types. There are many other features, if your interested in a specific one please ask.
Voters choice
An integral part of Geo-Failover is the Database Cluster. Regardless if your using SQL or mySQL, we have a solution for you. With SQL, we setup Always-on Availability Groups, a cluster made up of 3 servers, each server maintaining a vote of who should be primary. The primary server is the only one able to respond to SQL requests, and it needs at least 2 votes to maintain primary status, with one vote coming from itself. SQL maintains a master-slave topology, with only one server ever holding the primary status at one time. MySQL on the other hand, with the help of Galera clustering, maintains a Master-Master topology. It can respond to SQL requests on either server simultaneously. In some cases, you can actually do GEO-Load Balancing, so there’s no need to failover at all. Galera Clustering also requires 3 servers, with the 3rd server deciding who has priority should the databases run into a conflict, as well as assisting in remediation should one database go unavailable.
Follow the Master
Now that we have all of the parts we need, its time to add the final touches of automation. It’s a little complicated, but it works like this. The Geo-Failover router will always favor the Primary location, as long as its working. It monitors your primary domain using http codes. Should the primary fail, traffic will be forwarded to the secondary web server within seconds. If the primary comes back online, the router is configured to fail back immediately. However, there are other variables to contend with. When a web server queries the DB, it is a very chatty process, one that is not ideal over any significant distance. So its important that the web servers only use their local DB for production traffic. So when a Web failover occurs, we need SQL to quickly follow, and that’s exactly what our SQL automation scripts do. With MySQL, you don’t have to worry about SQL failover, because both databases are already live.
Last call
Our Geo-Failover DR service has become very popular. If you think you may be interested, or if you have any questions, please don’t hesitate to give us a call. Ask for our Sales Manager, Chris Gentry. He will make sure we have a DR engineer available to answer any questions you may have. Regardless if you are an existing customer or a new customer, we can usually deploy this solution within 7 days with no downtime. In some cases it may require a scheduled reboot.There is no upfront cost, and we will give you the first month free if you mention this blog.
Tags: Windows Shared Hosting, Windows VPS HostingCategories: Business Tips, Developers, Hosting, Windows VPS Hosting